Instalación de un clúster Hadoop con Cloudera-Manager
0. Índice de contenidos.
- 1. Prerrequisitos.
- 2. Introducción y objetivos.
- 3. Requisitos necesarios
- 4. Preparación del entorno
- 5. Instalación de Cloudera-Manager
- 6. Cuando todo falla.
- 7. Siguientes pasos.
1. Prerrequisitos.
Si quieres aprovechar bien el contenido de este tutorial, deberás tener:
- conocimientos de la arquitectura de Hadoop. Nivel medio.
- conocimientos de administración de Linux. Nivel medio.
- conocimientos de administración de Redes/Seguridad. Nivel básico.
2. Introducción y objetivos.
El objetivo de este tutorial es aprender a instalar, configurar y monitorizar un cluster Hadoop en modo distribuido, mediante el framework Cloudera-Manager Enterprise, todo ello usando máquinas virtuales (mediante Vmware). Espero que os sea útil.
Cloudera-Manager es una plataforma de administración de Cloudera open source, para la gestión de Clústers Hadoop. Este tipo de frameworks facilitan la gestión manual que supone la administración de un clúster, ya que se trata de un trabajo complicado y bastante propenso a errores. Pensar en todos los pasos que hay que seguir en cada nodo: instalación del paquete de hadoop, configuración de variables de entorno, definición de archivos de configuración, definir permisos y reglas de seguridad, levantar demonios, formateo del sistema HDFS, etc.

Logo de Cloudera-Manager
Cloudera-Manager no es la única opción en el mercado como hemos visto en otros tutoriales (Instalación de un entorno Hadoop con Ambari), pero es la solución líder actualmente por varios motivos como veremos más adelante.
Definiremos un clúster distribuido mediante uso de máquinas virtuales, lo que nos permitirá “jugar” con cloudera-manager. Hay otras opciones a la hora de definir un clúster: por ejemplo podemos interconectar varios PCs, o bien podemos trabajar con servicios en la nube (EC2 de Amazon, Azure de Microsoft, RackSpace, etc.). La opción que veremos en este tutorial es la más asequible en muchos aspectos.
3. Requisitos necesarios.
Para seguir los pasos en este tutorial necesitaremos:
- Vmware Workstation versión 11 para Windows (cualquiera que pueda realizar Snapshots nos servirá). Yo he usado la versión 11 de evaluación de 30 días.
- Imagen de un Sistema Operativo Linux en Vmware: lo usaremos como nodo inicial donde correrá el instalador de cloudera-manager. Yo he usado una máquina virtual Linux CentOS v6 (64 bits, requerido por Hadoop) y 8Gb RAM. Os recomiendo la distribución CentOS ya que es la más popular dentro de la comunidad Hadoop.
Mientras mayor capacidad de recursos hardware tenga tu equipo, más nodos podrás incluir en tu clúster. Usar una distribución limpia de Hadoop, sin ninguna instalación activa o previa.
Cloudera manager acepta las siguientes distribuciones en 64 bits: - Red Hat Enterprise Linux 5 (Update 7 or later recommended)
- Red Hat Enterprise Linux 6 (Update 4 or later recommended)
- Oracle Enterprise Linux 5 (Update 6 or later recommended)
- Oracle Enterprise Linux 6 (Update 4 or later recommended)
- CentOS 5 (Update 7 or later recommended)
- CentOS 6 (Update 4 or later recommended)
- SUSE Linux Enterprise Server 11 (Service Pack 2 or later recommended)
- Ubuntu 10.04 LTS (Only supports CDH 4.x)
- Ubuntu 12.04 LTS
- Ubuntu 14.04 LTS
- Debian 6.0 (Only supports CDH 4.x)
- Debian 7.0
Básicamente esto es todo lo que necesitas. En mi caso, al disponer de 8GB de RAM, he decidido definir la siguiente arquitectura:
- Servidor primario para la instalación de cloudera-manager con: 3,5GB RAM+2 cores. Podría haber dedicado menos, pero prefiero trabajar cómodamente con el escritorio X11, por lo que requiere un poco más de RAM.
- Cuatro (4) Nodos secundarios con los demonios Hadoop, cada uno de ellos con: 1 GB RAM+1 core+1 GB disco. Linux no requiere mucho más. Bien es cierto que Hadoop requiere más RAM, pero ya veremos que esto se puede resolver.
En total dedicaré el 90% de mi RAM disponible (3,5+4) al clúster en Vmware.
4. Preparación del entorno.
Partimos de una imagen en Wmware tal y como se ha indicado anteriormente. Antes de proceder con el clonado de esta imagen, debemos realizar una serie de configuraciones en la misma de forma que ahorremos trabajo. Para ello:
- Dentro de Linux, debemos desactivar la seguridad de SELinux (Security-Enhanced Linux) ya que de lo contrario no podremos continuar. Para ello editaremos el siguiente fichero:
…cambiando la propiedad a “disabled”:
Comprobamos el nuevo estado mediante:NOTA: estos comandos deben lanzarse mediante el usuario ‘root’ o en su defecto mediante un usuario en la lista de ‘sudoers’, tal y como yo estoy haciendo. - Durante la instalación, necesitamos tener abiertos ciertos puertos por lo que desactivaremos el firewall de CentOS mediante:
- Registramos las IPs de cada nodo en el fichero “/etc/hosts” por comodidad. Por ahora sólo conocemos la IP privada de la única máquina virtual que tenemos, pero podemos inventarnos el resto. Más adelante se corregirá:
La IP privada se obtiene mediante (suponiendo que sólo tenemos una interfaz de red):
- Los siguientes pasos nos permitirán acceder a cada nodo sin password, lo cual es recomendable durante la instalación de cloudera-manager. Para ello, generamos una clave pública sin password:
Esto nos genera el archivo “/root/.ssh/id_rsa.pub” con la clave pública. También debéis generar un fichero de clave privada (.pem) que será requerido posteriormente. Ambos ficheros (“.pub” y “.pem”) se añadirán a la lista de claves autorizadas de la siguiente forma:
Conviene reiniciar la máquina virtual en este punto, mediante “reboot”. - La distribución Linux de la que yo parto inicia el entorno gráfico X11. En mi caso haré que en el arranque se inicie en modo texto para que no consuma recursos innecesarios. Para ello en la última línea del fichero “/etc/inittab” reemplazamos el código 5 por 3, de forma que nos quede:
En mi caso, además tengo que adaptar el teclado modificando el fichero “/etc/sysconfig/keyboard”. - A continuación prodecemos con el clonado de máquinas, para obtener los 4 nodos. Para ello apagamos la máquina virtual (Power Off) y la seleccionamos en Vmware para acceder al menú “VMàSnapshotàTake Snapshot…”. Esto sólo hay que hacerlo una vez.
Posteriormente procedemos al clonado. Nuevamente sobre nuestra máquina virtual en Vmware, accedemos al menú “VMàManageàClone…”. Damos en next, pero elegimos clonar a partir de una snapshot: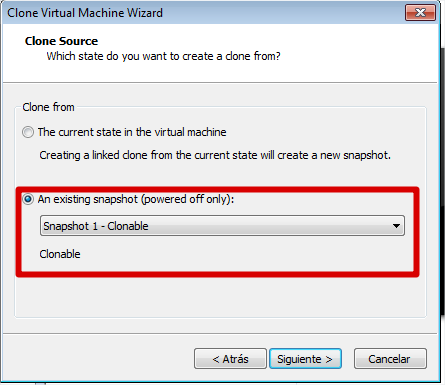
Para el resto de ventanas elegirimos las opciones por defecto, salvo en el nombre de la máquina clonada que asignaremos nombres descriptivos como: nodo1, …, nodoN.
El aspecto final de nuestro cluster en Vmware será el siguiente (podéis crear una carpeta para mayor claridad):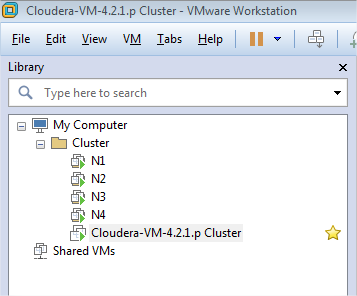
- Antes de arrancar cada máquina, procedemos a configurar algunos parámetros en Vmware tal y como se ha indicado anteriormente:
a. Memoria: 1GB RAM.
b. CPUs: 1 core. - Procedemos a arrancar los nodos y en cada uno de ellos realizamos las siguientes acciones; cambiamos el nombre del host para que coincida con el configurado en el fichero de hosts:
Lo hacemos permanente editando la propiedad HOSTNAME en el fichero:
Actualizamos la IP de nuestro nodo en el fichero “/etc(hosts” tal y como hemos hecho antes.
5. Instalación de Cloudera-Manager.
- Una vez preparado el entorno, procedemos a descargarnos el instalador de cloudera-manager mediante:
- Concederemos permisos de ejecución al paquete y lo ejecutaremos:
Nos aparecerán una serie de ventanas en las que iremos avanzando con las opciones por defecto (no es necesario instalar jdk 1.7):
Al finalizar nos saldrá el siguiente popup indicando que ya podemos acceder al servidor web (tardará unos minutos en arrancar el servidor web):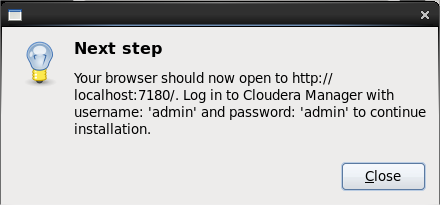
- Accedemos al servidor web (bien desde linux o windows) como admin/admin:
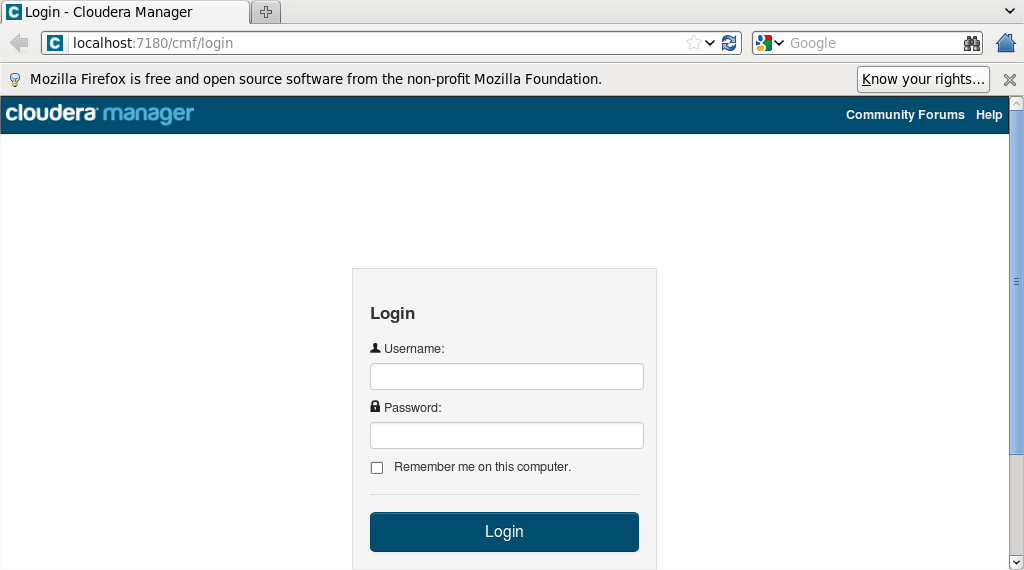
Seleccionamos la versión Enterprise Data Hub:
Indicamos la lista de nodos: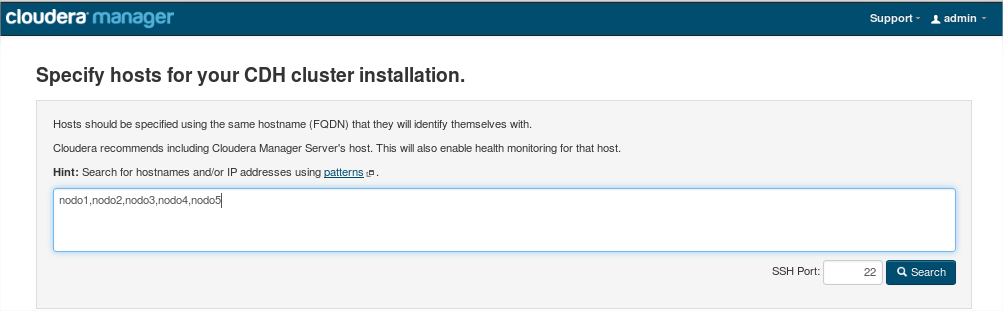
Comprobamos que hay conectividad en todos los nodos: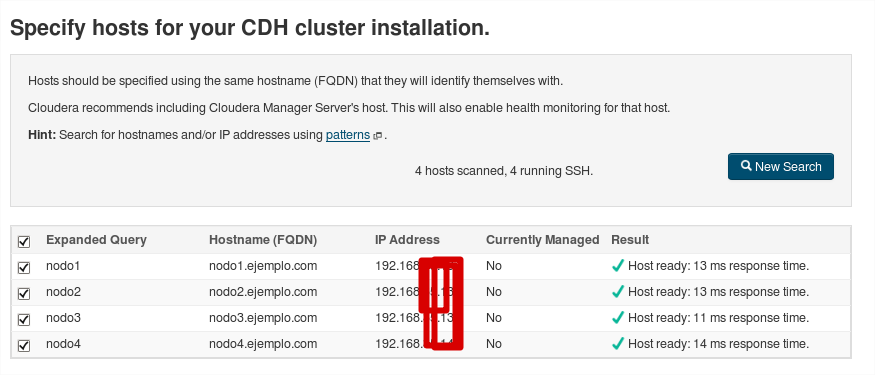
Indicamos el usuario a usar (root si disponemos del mismo, o bien otro usuario con privilegios). También especificamos el fichero “.pem” con la clave privada ya generada anteriormente: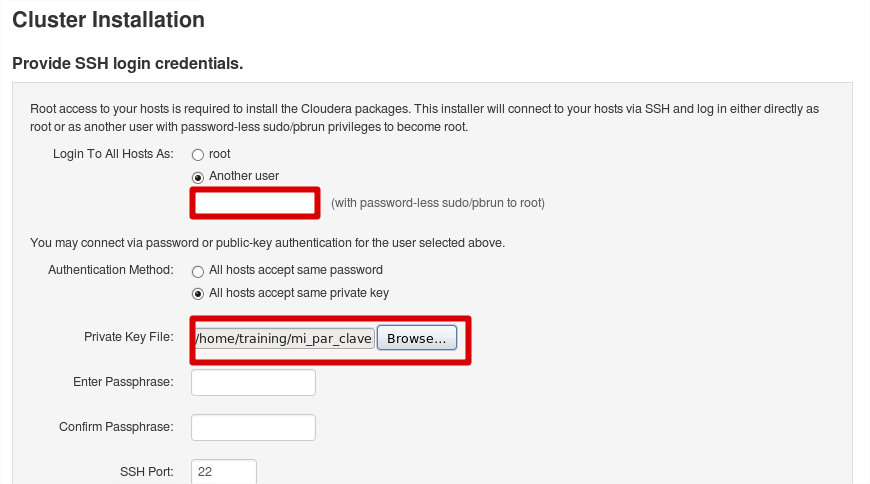
A continuación comenzará la instalación de cloudera-manager-agent en cada nodo (el tiempo de este paso depende de la velocidad de tu red):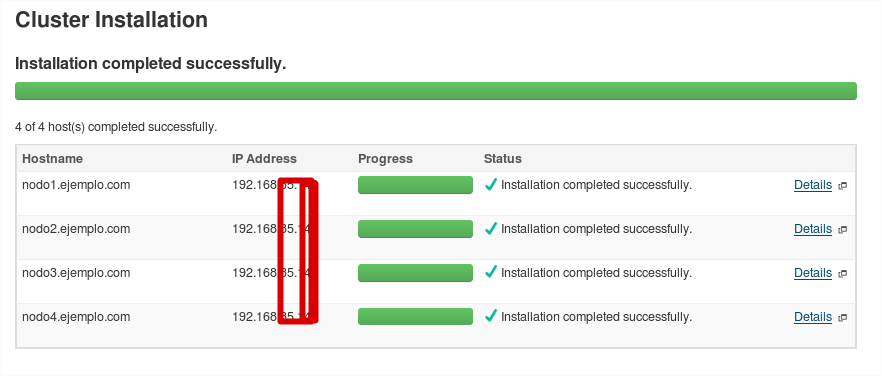
Una vez completada la instalación, avanzaremos por las siguientes ventanas con los valores por defecto: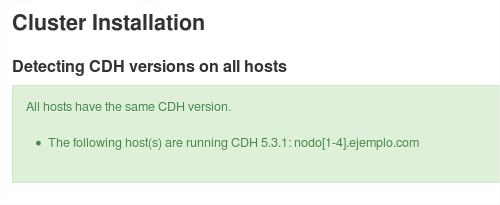
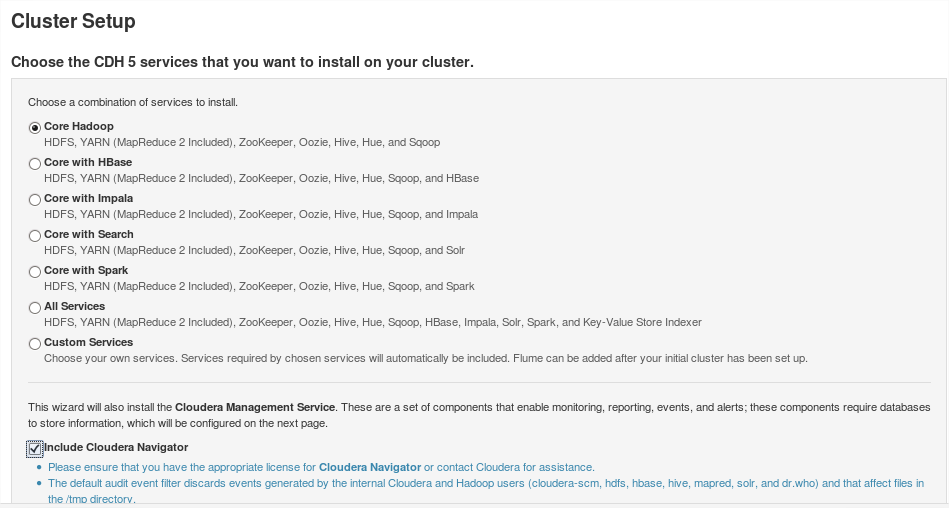
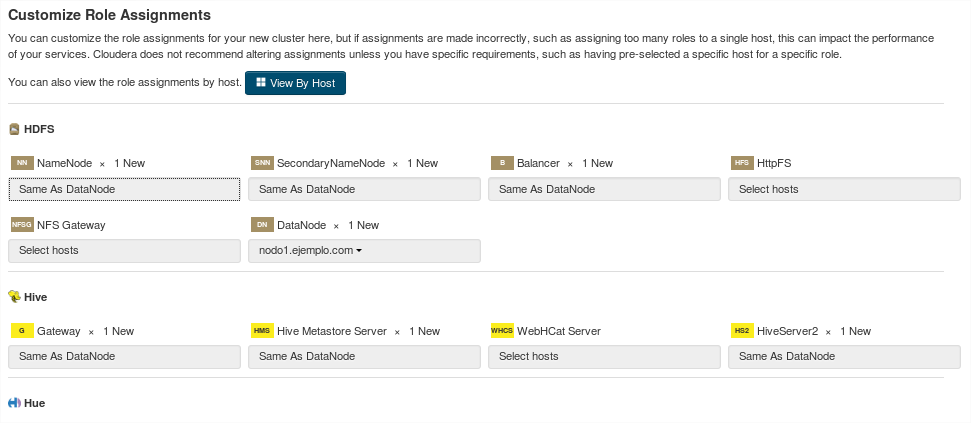
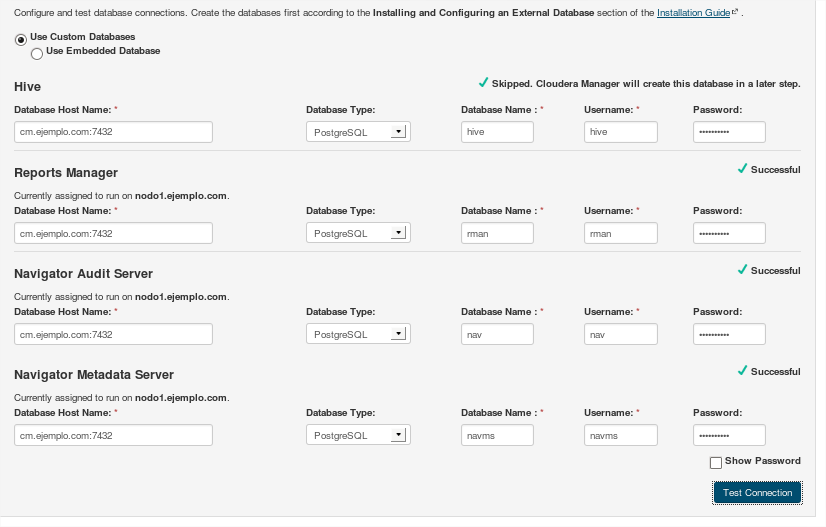
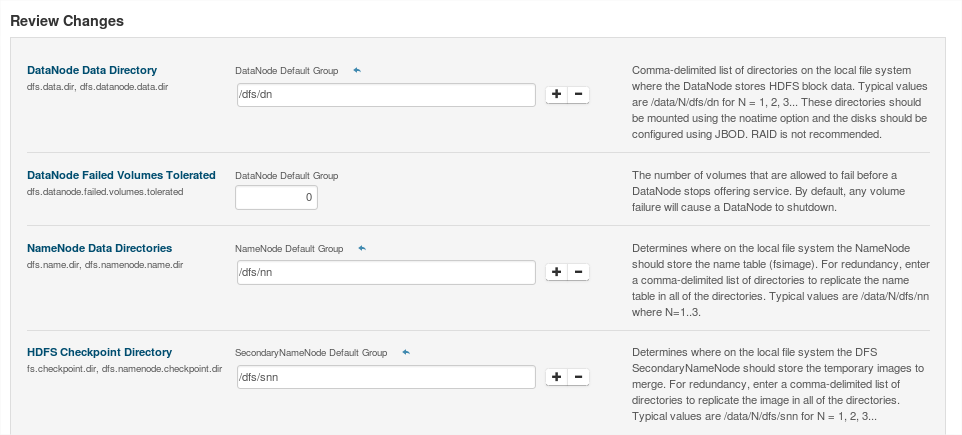
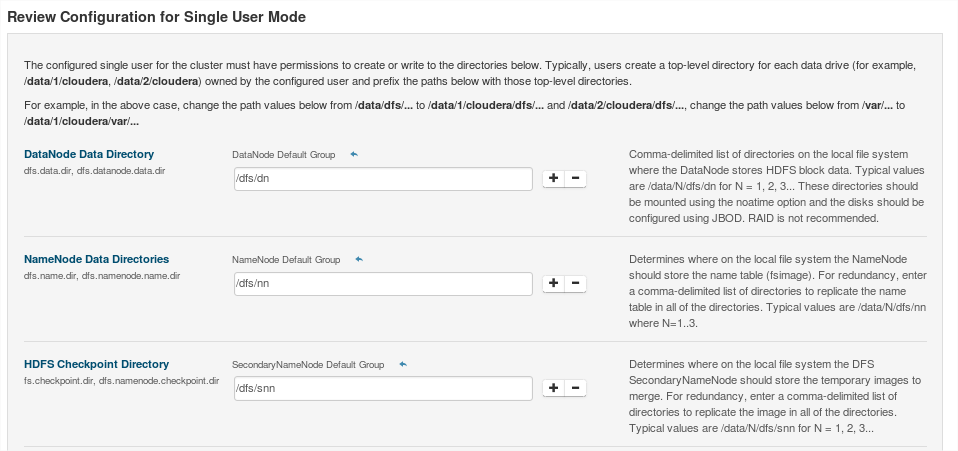
A continuación se iniciarán cada uno de los demonios en cada nodo: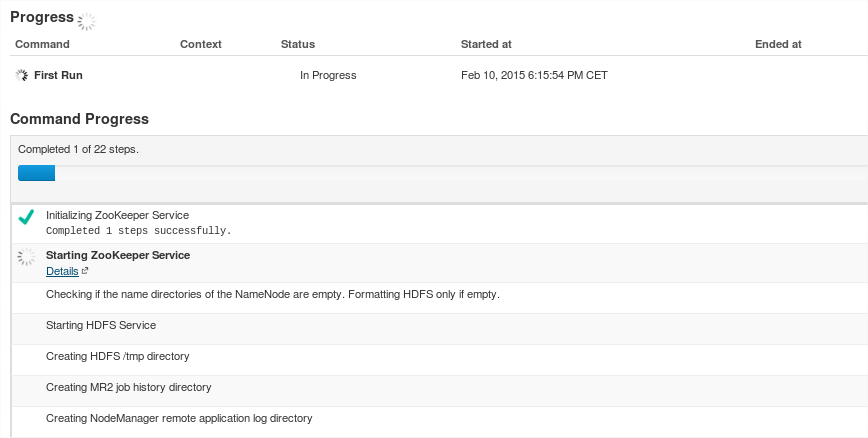
…y se nos mostrará la ventana principal: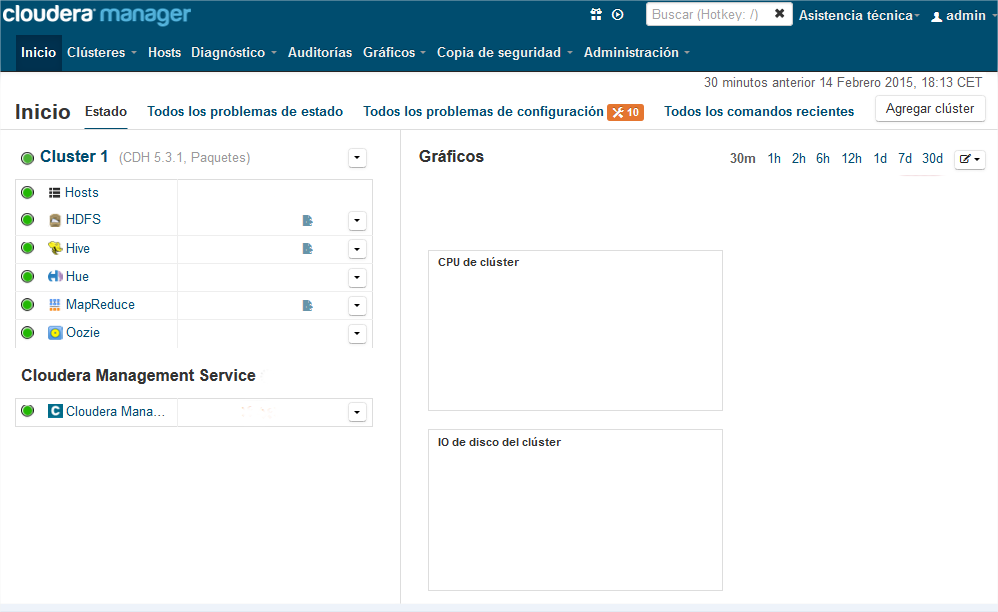
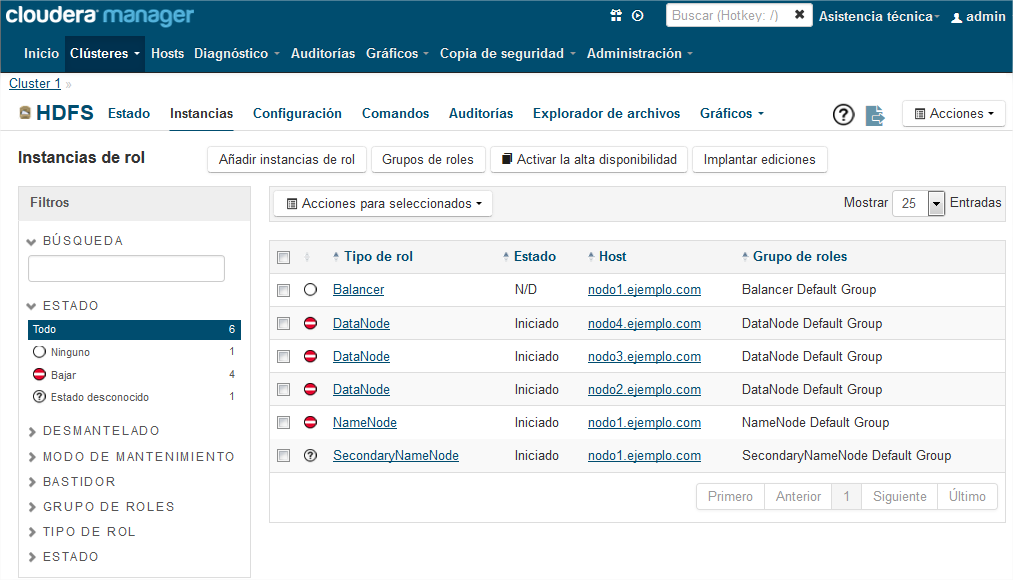
Ya tenemos listo nuestro clúster hadoop gestionado con Cloudera Manager. En la pestaña de “Inicio” podemos ver el estado general del cluster y los problemas si los hay. Conviene revisar cada uno de los Hosts para comprobar que todos los demonios están levantados: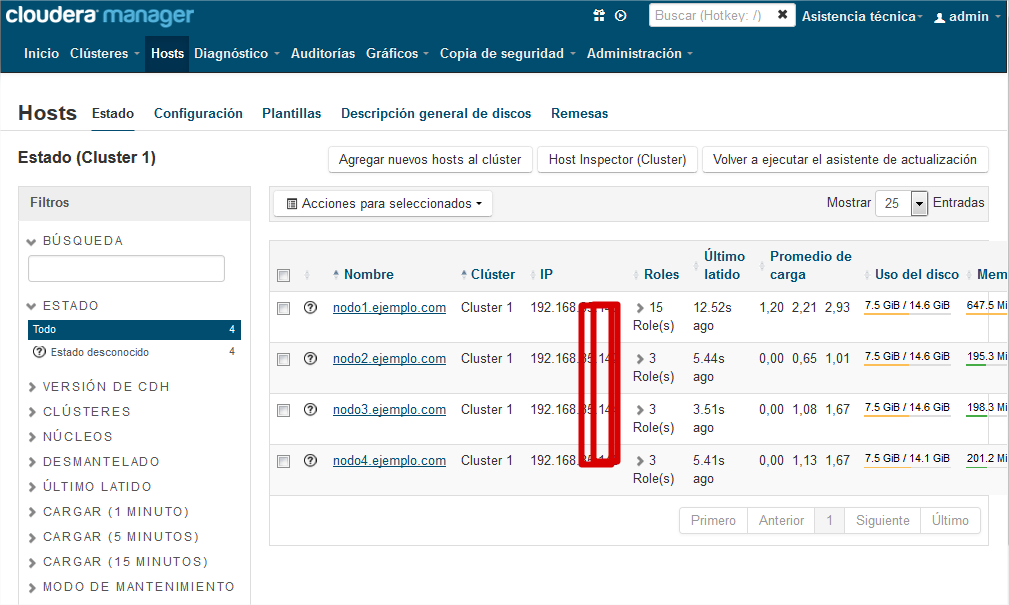
6. Cuando todo falla.
Uno de los inconvenientes del proceso de instalación en este tipo de herramientas es que lanzan scripts batch (python, perl, etc.) “transparentes” al usuario para avanzar con la instalación. Las acciones que estos scripts ejecutan, dependen de muchas variables del entorno para que terminen satisfactoriamente (permisos y credenciales, versiones de software, dependencias con paquetes rpm, seguridad, puertos y reglas del proxy, requisitos hardware, etc.).
Lo más probable es que tengáis que repetir el proceso de instalación varias veces hasta que tengáis todos los requisitos hard/soft bien configurados. La gran mayoría ya se han tratado en este tutorial pero siempre puede quedar alguno por comentar, lo cual depende de la configuración de vuestro SO. Vamos a comentar a continuación cómo salir airoso ante un error durante la instalación de cloudera manager.
Lo primero es saber el estado de nuestra instalación. ¿Sigue en curso? ¿Está detenida por algún error?. Para ello podemos consultar los procesos en busca del que nos preocupa:
Si vemos que están idle y no progresan, mala pinta. Aunque lo más elegante es seguir los logs de la instalación mediante:
En caso de finalizar la instalación ¿Cómo sé el estado de mi servidor de cloudera manager? Con el siguiente comando es fácil:
Aunque personalmente me fío más del ps. Siempre habrá 3 procesos corriendo si todo va bien: el servidor de la BBDD Postgres, el servidor de cloudera, y el job java asociado:
Si estáis en un callejón sin salida en la instalación y queréis volver a empezar desde cero, tenéis varias opciones. La elegante pero que no suele funcionar, es ejecutar el desistalador:
La otra opción es limpiar nuestro equipo de la instalación de cloudera. Para ello:
- Parar todos los servidores de cloudera manager (si no funciona, matar los procesis con “kill”):
- Eliminar todo rastro de la instalación en el repositorio yum (si no funciona, forzar el borrado con rpm: “rpm -e –noscripts”):
- Limpiar la cache de yum:
En ocasiones, al volver a iniciar una nueva instalación, puede aparecer el mensaje: “cloudera-scm-server dead but pid file exists”. Para resolverlo debemos detener todos los servidores de cloudera manager y eliminar el siguiente fichero:
El mismo procedimiento debemos seguir cuando el proceso de instalación se quede bloqueado en el paso “cloudera manager acquiring installation lock”. Debemos borrar el fichero de bloqueo en cada uno de los nodos:
Durante el proceso de instalación, tener en cuenta que:
- Podemos “abandonarlo” temporalmente, cerrando el explorador sin problemas. Cuando deseemos continuar, basta con volverse a conectarse al puerto 7180. La instalación seguirá en background.
- No podemos cambiar ninguna IP (en caso de trabajar con IPs dinámicas). De ser así, la instalación fallará y la solución pasa por cambiar las IPs manualmente en la BBDD postgres de cloudera manager. Nada recomendado.
- La navegación dentro del proceso de instalación no está muy fina, y a veces se nos muestra la opción de pulsar en el botón “Back” para volver al paso anterior, cuando realmente no es posible. Si estáis en este punto, sólo os queda volver a comenzar (“Abort instalation”).
- El botón “Abort instalation” cancela la instalación obligando a iniciarla desde el principio, pero no limpia el sistema de archivos temporales.
- La instalación hace uso de caché, de forma que sólo el primer intento es el que lleva tiempo. Los subsiguientes son más rápidos.
Un aspecto positivo a comentar de cloudera manager sobre otras soluciones similares, es que el proceso de instalación no se detiene si alguno de los demonios (maestro o esclavo) no arranca en algún nodo, siempre que no sea un demonio vital como el NameNode para HDFS. A posteriori podremos solucionar el problema y reintentar iniciar el demonio que daba problemas.
7. Siguientes pasos.
Una vez terminado de instalar nuestro clúster, los siguientes pasos que recomiendo (ya fuera de este tutorial) serían lanzar un job hadoop y ver el restultado desde el cuadro de mando en el Host Monitor, así como estudiar las distintas métricas que nos proporciona cloudera manager. Lo más rápido para ello, es usar la librería de ejemplos que viene con la distribución descargada, y lanzar por ejemplo el estimador del número pi para 12 mappers y 3000 muestras:
Otro ejercicio interesante que nos permite cloudera manager es jugar con los nodos: tirar un nodo, moverlo de ubicación, añadir nodos, y volver a lanzar nuestro job hadoop para ver los cambios introducidos en el cluster.
También por comodidad, conviene hacer las IPs de cada nodo (o máquina virtual) estáticas, para que no cambien entre reinicios de Vmware. Para ello:
- Modificar el fichero de configuración de la interfaz de red, editando el archivo:
El nombre del fichero puede variar pero normalmente será “ethN”. Debe corresponderse con el que sale al ejecutar:
Debéis poner (el resto de parámetros los mantenéis):
La IP estática la asignáis vosotros (por ejemplo para los 4 nodos: …101, …102, …103 y …104) y el gateway será el de vuestro router. También debéis indicar el nombre del servidor que deseéis en el siguiente archivo:
Debéis poner:
Listo. Reiniciad la red con:
No hay comentarios:
Publicar un comentario